As a Cloud Solutions Architect covering the Azure VMware Solution (AVS), I help many customers get their pilot kick-started. Typically this includes helping customers get their prerequisites done for the AVS service, deploying and connecting AVS, deploying and connecting Hybrid Cloud Extension (HCX), and doing a test migration using HCX. Having done a number of these now, there is some valuable stuff I need to write down before I forget! And hopefully, this will be helpful for other people. I will try not to be redundant to PG’s fantastic blog series for troubleshooting. For this saga, the answer was relatively simple and had to do with knowing your vSphere environment. So the hope is you find value in the journey and not just the answer.
Environment Details:
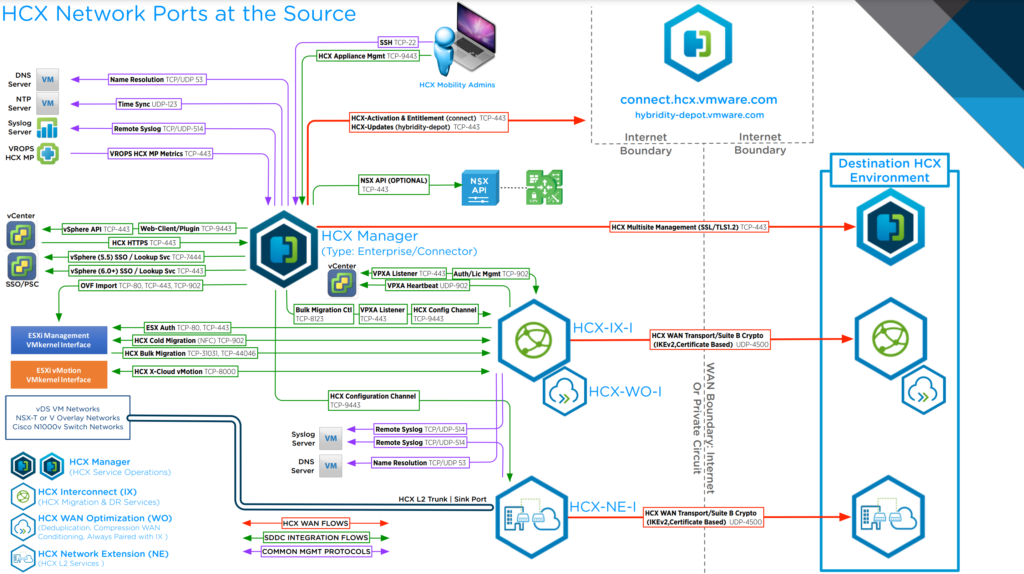
In this saga we are at the end of our HCX setup and we are now trying to test migrations. The goal was to use a bulk migration, which is a replication-assisted migration. Under the hood, this is using vSphere replication. As I will commonly do, I will reference Gabe’s port diagram to help understand what we are using .
So, we have a service mesh created and all appliances show green. Tunnel status is up. However, when we kick off a bulk migration of a VM, it gets to “starting replication” but the progress bar stays at 0% for hours.
Doing some google searches of the behavior, I’m led to this KB: https://kb.vmware.com/s/article/79020
In summary, the KB says if you are stuck at 0% and do not progress you likely have an internal firewall blocking traffic between the HCX components and the vSphere infrastructure. This makes sense to me because if it was WAN or firewall related to the destination environment, HCX is pretty good at alerting and providing those details in a diagnostics run (which we had ran.) While the migration job is still running, let’s use TCP dump to see if data is being sent. To do this, we need to log in to the IX and drop into a shell through the HCX connector on-prem.
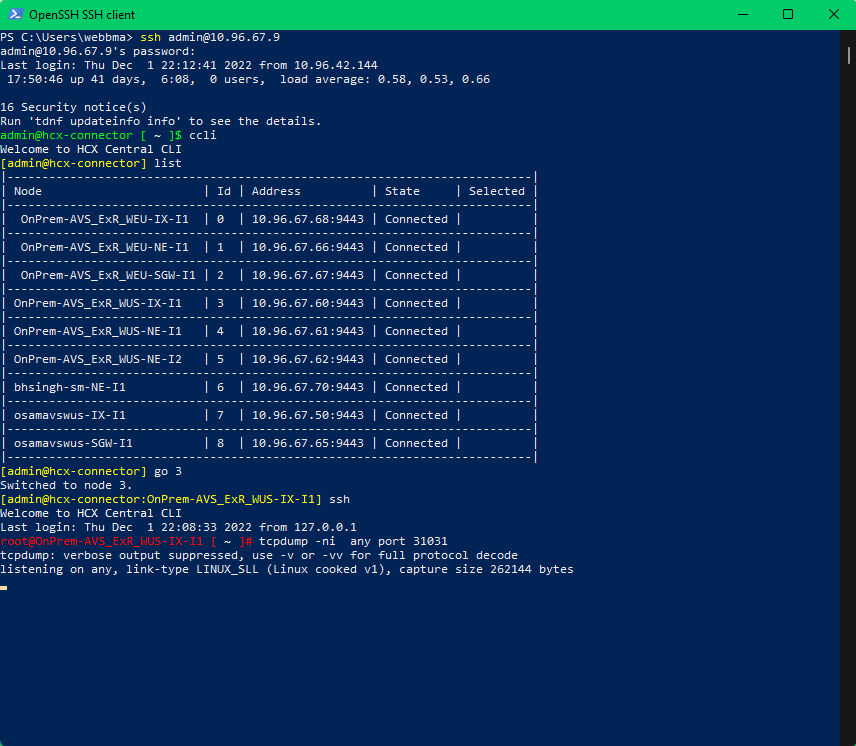
Let’s review the above screenshot:
- I logged into the hcx manager/connector on-premise using ssh
- I went into the “ccli” and performed a “list” command which shows all active appliances in a service mesh
- The specific environment i wanted to troubleshoot was our West US service mesh, and i want to get into the IX appliance because it is responsible for bulk migrations
- Once i went to the IX appliance, i dropped into a shell and ran a tcp dump on 31031 which is the port used for replication.
As you can see, there is no data after that command. This is live listening, and if migrations are started as the HCX UI claims, then we would see data flowing. Lets look at a tcpdump on an IX appliance with an active replication so we know what we should see.
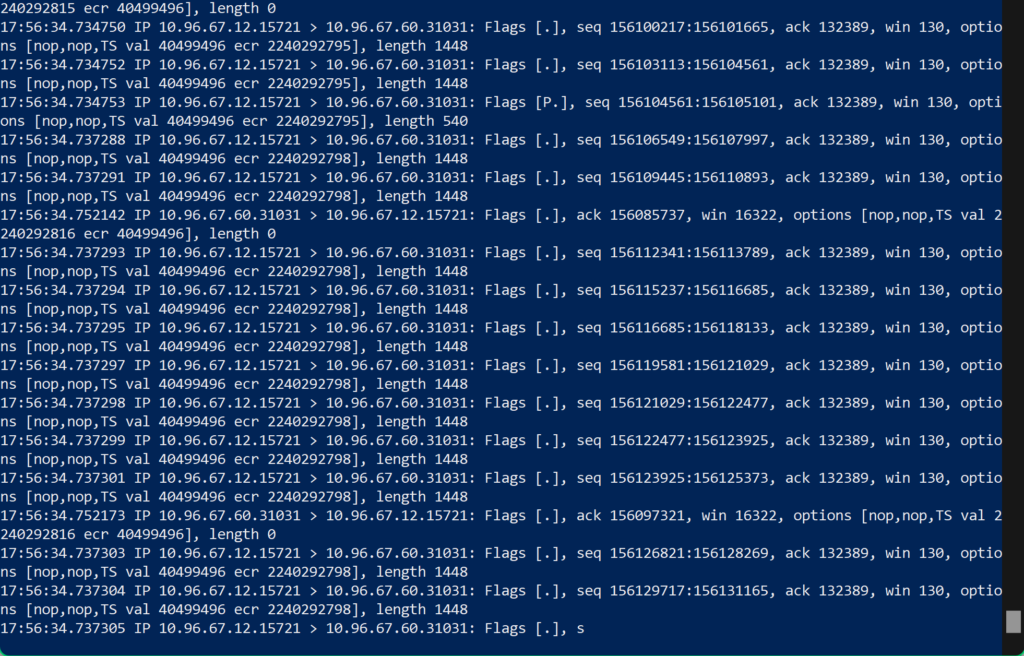
So now that we know replications aren’t being sent, lets reach out to the firewall team to see if the IX has any denys to the ESXi hosts. Sure enough the IX does have denys, however we are told its to their vSphere replication network.
Oh! We have a replication network?
Well there is our problem, our service mesh does not define a replication network. After adding the vSphere replication network into a network profile, adding it to our compute profile, and updating our service mesh, HCX bulk migrations now complete successfully.
Ultimately, there are many ways to reach the same conclusion. The point of this story is to show how you can reach the IX appliance to use typical linux troubleshooting to identify a problem. HCX uses many end points in your vSphere environment, so its not uncommon to run into firewall or networking issues blocking progress. Make sure when you deploy HCX in your environment, you extensively review HCX’s network port requirements. You can find an extensive list here, and use the diagram by Gabe to get an high level idea of how the tool functions across your network.